
PDF is the most widely used digital document format. We can parse PDF documents and extract text and images from them programmatically. It could be useful in several cases, such as text analysis, information retrieval, document conversion, etc. In this article, we will learn how to extract text and images from PDF documents using Java.
The following topics shall be covered in this article:
- Java API to Extract Text and Images from PDF Documents
- Extract Text from PDF Documents using Java
- Extract Text from Specific Pages of a PDF Document using Java
- Get Images from PDF Documents using Java
- Extract Images from Specific Pages of a PDF Document using Java
- Extract and Save Images to Files using Java
Java API to Extract Text and Images from PDF Documents
For extracting text and images from PDF documents, we will be using GroupDocs.Parser for Java API. It allows the extraction of raw, formatted, and structured text, metadata, and images from files of the supported formats. Please either download the JAR of the API or add the following pom.xml configuration in a Maven-based Java application.
<repository>
<id>GroupDocsJavaAPI</id>
<name>GroupDocs Java API</name>
<url>https://repository.groupdocs.com/repo/</url>
</repository>
<dependency>
<groupId>com.groupdocs</groupId>
<artifactId>groupdocs-parser</artifactId>
<version>22.3</version>
</dependency>
Java PDF Text Extraction
We can parse any PDF document and extract text by following the steps given below:
- Firstly, load the PDF file using the Parser class.
- Next, call the Parser.getText() method to extract text from the loaded document.
- Then, get results in the TextReader class object.
- Finally, call the TextReader.readToEnd() method to read all characters from the current position to the end of the text reader and return them as one string.
The following code sample shows how to extract text from a PDF file using Java.
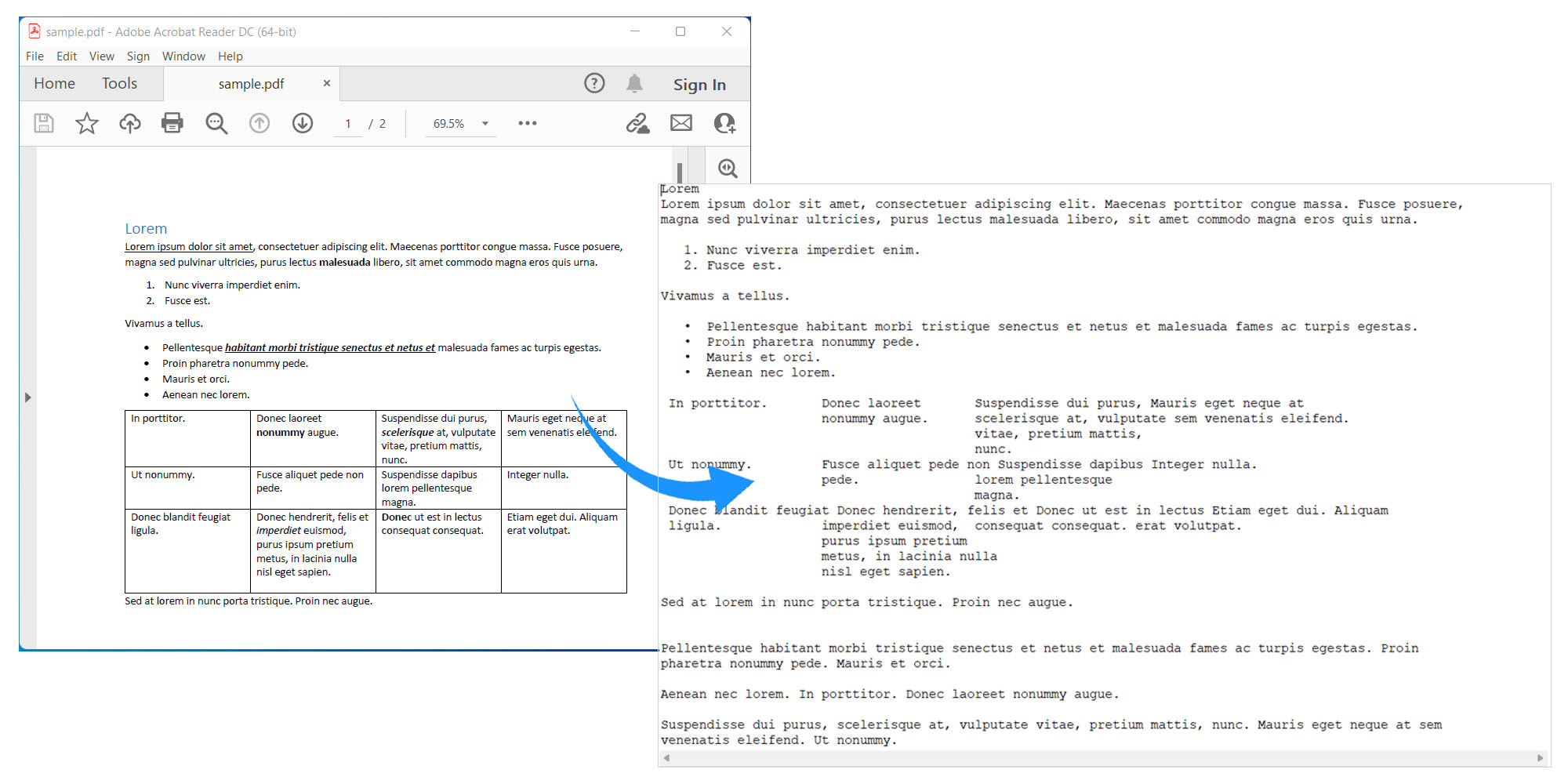
Extract Text from PDF Documents using Java
Extract Text from Specific Page of a PDF Document using Java
You can parse a PDF document and extract text from a specific page by following the simple steps mentioned below:
- Firstly, load the PDF file using the Parser class.
- Next, get document information using the Parser.getDocumentInfo() method.
- Then, check if the IDocumentInfo.getPageCount() is not zero.
- After that, call the Parser.getText() method with page index to extract text from that specific page and get results in TextReader class object.
- Finally, show results by calling the TextReader.readToEnd() method to read the extracted text.
The following code sample shows how to extract text from a specific page using Java.
The API also enables to check whether the document supports the text sxtraction feature. For this purpose, we can use Parser.getFeatures().isText() property. Please read more about supported features.
Extract Images from PDF (Java)
We can parse any PDF document and extract images by following the steps given below:
- Firstly, load the PDF file using the Parser class.
- Next, call the Parser.getImages() method and obtain collection of PageImageArea objects from the loaded document.
- Then, Check if the collection is not null.
- After that, iterate over all the found images.
- Finally, show images details.
The following code sample shows how to get images details from a PDF file using Java.
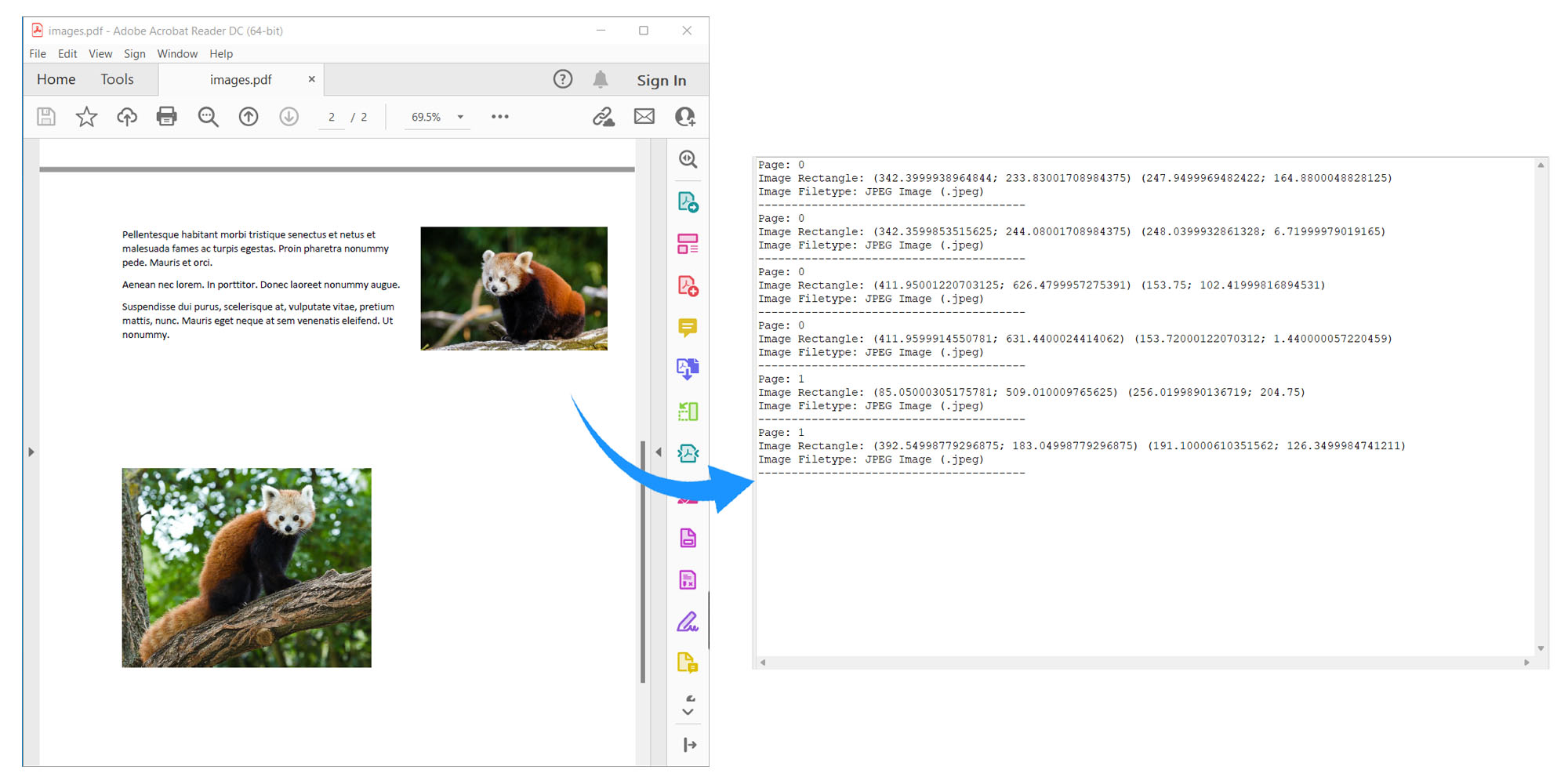
Get Images from PDF Documents using Java
Extract Images from Specific Page of a PDF Document using Java
We can extract images from a specific page by following the simple steps mentioned below:
- Firstly, load the PDF file using the Parser class.
- Next, get document information using the Parser.getDocumentInfo() method.
- Then, check if the IDocumentInfo.getPageCount() is not zero.
- After that, call the Parser.getImages() method with page index to extract images from that specific page.
- Finally, iterate over all the found images and show details.
The following code sample shows how to extract images from a specific page using Java.
Extract and Save Images to Files using Java
We can also save the extracted images by following the steps given below:
- Firstly, load the PDF file using the Parser class.
- Next, call the Parser.getImages() method and obtain collection of PageImageArea objects from the loaded document.
- Then, create an instance of the ImageOptions class and set the image format.
- After that, iterate over all the found images.
- Finally, save using the save() method. It takes the output file path and ImageOptions as arguments.
The following code sample shows how to extract and save images to files using Java.
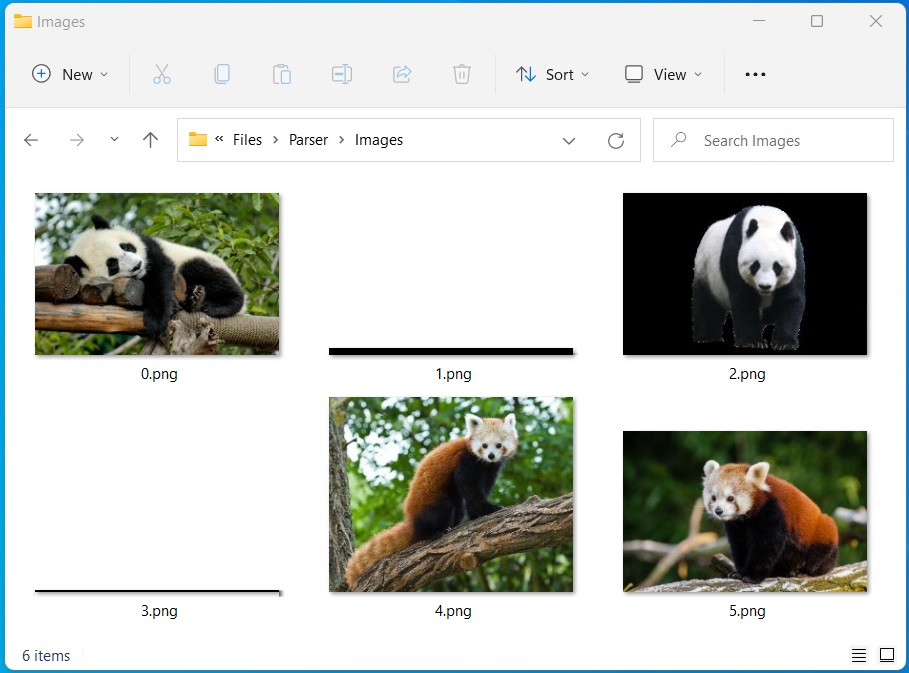
Extract and Save images to files using Java
Get a Free License
You can try the API without evaluation limitations by requesting a free temporary license.
Conclusion
In this article, we have learned how to:
- extract all the text from a whole PDF document or specific pages of the document using Java;
- extract images from a PDF file programmatically;
- save extracted images on a local disk.
Besides, you can learn more about GroupDocs.Parser for Java API using the documentation. In case of any ambiguity, please feel free to contact us on the forum.