
Web Scraping is a technique used to extract data from websites. It helps to automate the process of extracting data from websites and HTML files. As a C# developer, we can easily inspect, capture and extract data, such as images, video, audio, etc., from the web pages. In this article, we will learn how to perform web scraping with HTML parsing using C#.
The following topics shall be covered in this article:
- C# Web Scraping API
- Read and Extract HTML using C#
- Inspect Document Elements using C#
- Find Specific Element using Filters in C#
- Query Data from HTML using C#
- Extract using CSS Selector in C#
C# Web Scraping API
For web scraping from HTML files or URLs, We will be using Aspose.HTML for .NET API. It is an advanced HTML processing API that allows to generate, modify, extract data, convert and render HTML documents without any external software. Please either download the DLL of the API or install it using NuGet.
PM> Install-Package Aspose.Html
Read and Extract HTML using C#
We can read and extract HTML from any HTML document by following the steps given below:
- Load an HTML document using the HTMLDocument class.
- Display the inner HTML of the file to the console.
The following code sample shows how to read and extract HTML content using C#.
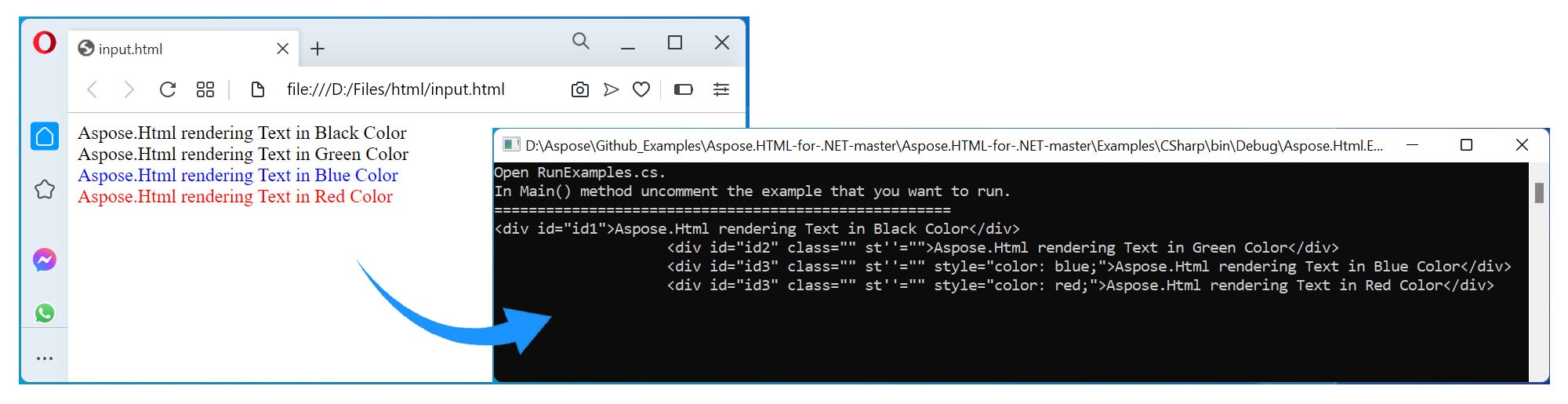
Read and Extract HTML using C#.
Similarly, we can read and extract HTML from live websites as shown below:
Inspect Document Elements using C#
We can inspect the document and its elements by following the steps given below:
- Load an HTML document using the HTMLDocument class.
- Get the HTML element of the document.
- Get the first/last elements of the HTML element.
- Display element details such as TagName, TextContent.
The following code sample shows how to inspect the document elements using C#.
Find Specific Element using Filters in C#
We can use custom filters to find a specific element such as get all images, links, etc. For this purpose, the API provides the TreeWalker interface. It allows navigating a document tree or subtree using the view of the document defined by their whatToShow flags and filter (if any). We can find specific elements using filters by following the steps given below:
- Define filters using the NodeFilter class and override the AcceptNode() method.
- Load an HTML document using the HTMLDocument class.
- Call the CreateTreeWalker() method. It takes root node, what to show, and NodeFilter as arguments.
The following code sample shows how to find specific elements using C#.
Query Data from HTML using C#
We can also use XPath Query to query data from an HTML document by following the steps given below:
- Load an HTML document using the HTMLDocument class.
- Call the Evaluate() method. It takes XPath expression string, document, and type as arguments.
- Finally, loop through the resulting nodes and display text
The following code sample shows how to query data with XPath queries using C#.
Extract using CSS Selector in C#
We can extract HTML content using CSS selectors as well. For this purpose, the API provides the QuerySelectorAll() method that allows navigation through an HTML document and searches the needed elements. It takes the query selector as a parameter and returns a matching NodeList of all the elements. We can query using CSS selectors by following the steps given below:
- Load an HTML document using the HTMLDocument class.
- Call the QuerySelectorAll() method. It takes the query selector as an argument.
- Finally, loop through the resulting list of elements.
The following code sample shows how to extract HTML content using CSS selectors in C#.
Get a Free License
Please try the API without evaluation limitations by requesting a free temporary license.
Conclusion
In this article, we have learned how to:
- read and extract the content of an HTML document using C#;
- inspect Document Elements and find a specific element from HTML;
- query-specific data and extract data using CSS Selector.
Besides, you can learn more about Aspose.HTML for .NET API using the documentation. In case of any ambiguity, please feel free to contact us on the forum.